0x00 前言
周五快下班的时候,想着终于结束了一周挖坑种树的活,可以休息两天了。没想到,隔壁工地一朋友滴滴我,让我帮忙在一个脚本输出结果上增加两个字段,于是就有了本文。
注:学习别人的code编写思路,也是一种成长。
0x01 接收脚本
文件地址:[连接(原始和完善后均在)](链接: https://pan.baidu.com/s/1Xe496gG8fX2sPDp1CkO8MQ 提取码: p82b 复制这段内容后打开百度网盘手机App,操作更方便哦)
接收到脚本后,看到这是一个 nsfocus rsas V6版本的一个漏洞报告转存工具,也就是把HTML页面的漏洞转存为Excel形式。
简单的看了一下第三方库,核心库主要是 BeautifulSoup 和 openpyxl ,有点小蒙,毕竟近期都是试着用 pandas 来处理Excel,网页主要用 re 正则来匹配调试。
推荐一下这个正则工具,经常用,挺不错的。
下载地址:[百度云连接](链接: https://pan.baidu.com/s/1PPCJqJzA5IJ7cCsBISZQbQ 提取码: g8g6 复制这段内容后打开百度网盘手机App,操作更方便哦)
0x02 了解需求
需求其实在前面也提到了,在输出结果上增加两个字段,说起来简单,做起来,有点难啊,还是菜啊。。。
效果前:
效果后:
0x03 着手开始
当接收到一个陌生的工具代码时,快速的了解方式,莫过于从入口点开始回溯。再此之前,先整体看下这份代码。
1 2 3 4 5 from bs4 import BeautifulSoupimport reimport osfrom openpyxl import Workbookimport sys
可以看到使用了5个三方库,核心的为 bs4 和 openpyxl 。整体一共编写了6个函数模块,分别是:
1 2 3 4 5 6 1. getrisk() 2. gettype() 3. genfilelist() 4. extract_index() 5. extract_detail() 6. extract_info()
工具使用方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 目录架构:192.168 .3 .123 .html192.168 .3 .125 .html192.168 .3 .125 .html
0x04 程序入口点
翻到code最下面,可以看到如下:
1 2 3 if __name__ == '__main__' :1 ]
由上可知,那首先就先从核心函数模块开始看吧。
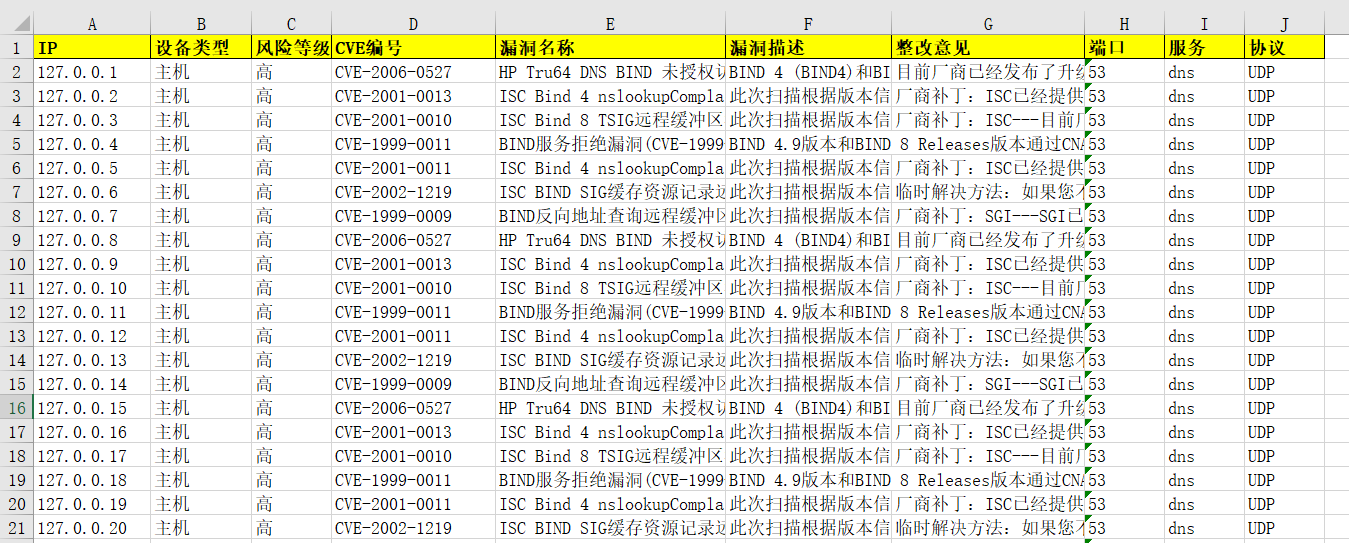
1 2 3 4 5 6 7 8 9 u'漏洞汇总.xlsx' 'IP' , u'设备类型' , u'风险等级' , u'CVE编号' , u'漏洞名称' , u'漏洞描述' , u'整改意见' , u'端口' , u'服务' , u'协议' ])'host/'
可以看出,这几行主要是创建一个Excel文档,并且设置相应的字段名,这里,我直接在后面添加上“服务”、“协议”两个需新增的字段名。
1 2 3 4 5 6 7 8 9 10 11 12 for filename in filelist:try :open (file, 'rb' )except :continue 'lxml' , from_encoding="utf8" )'div#content div.report_content table tr td table.report_table.plumb tbody tr.even td' )0 ].get_text()'div.vul_summary' )
这几行比较好理解,获取路径中的html报告,并且加载进 bs4 创建的内存中。
第十二行,直接利用第十行的 CSS 选择器,选中存在 IP 的部分,然后筛选 IP 值,放入 ip 变量中。
第十三行,是通过选择器把所有 div 瞄点的 class 值为 vul_summary 放入 vul_node 变量中,这个便于下面循环中,取相应所需的值。
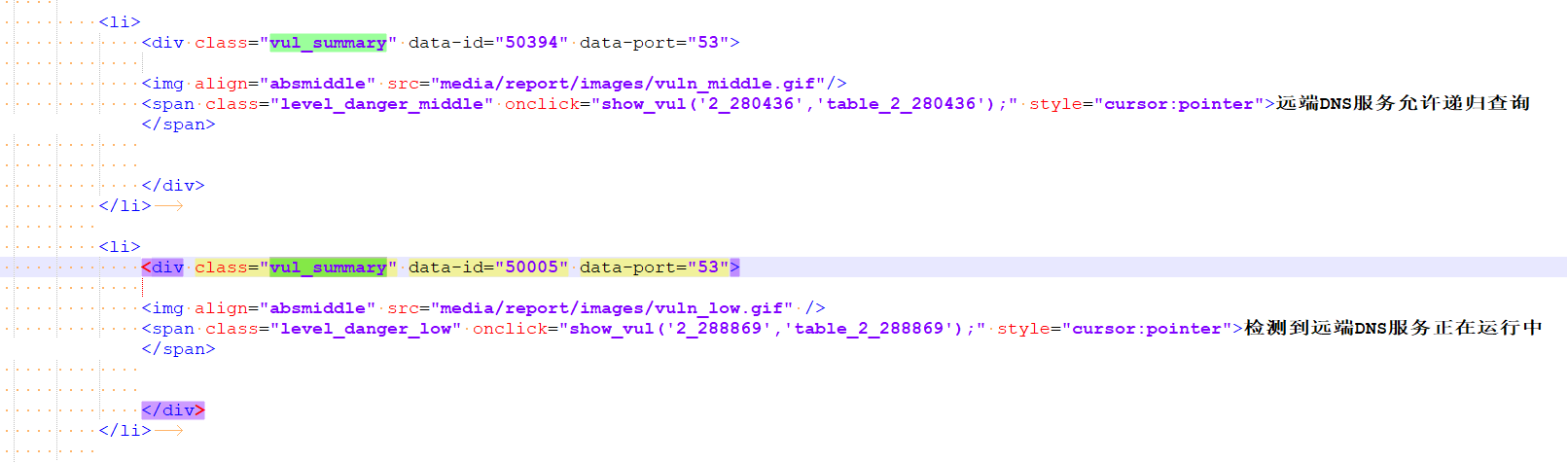
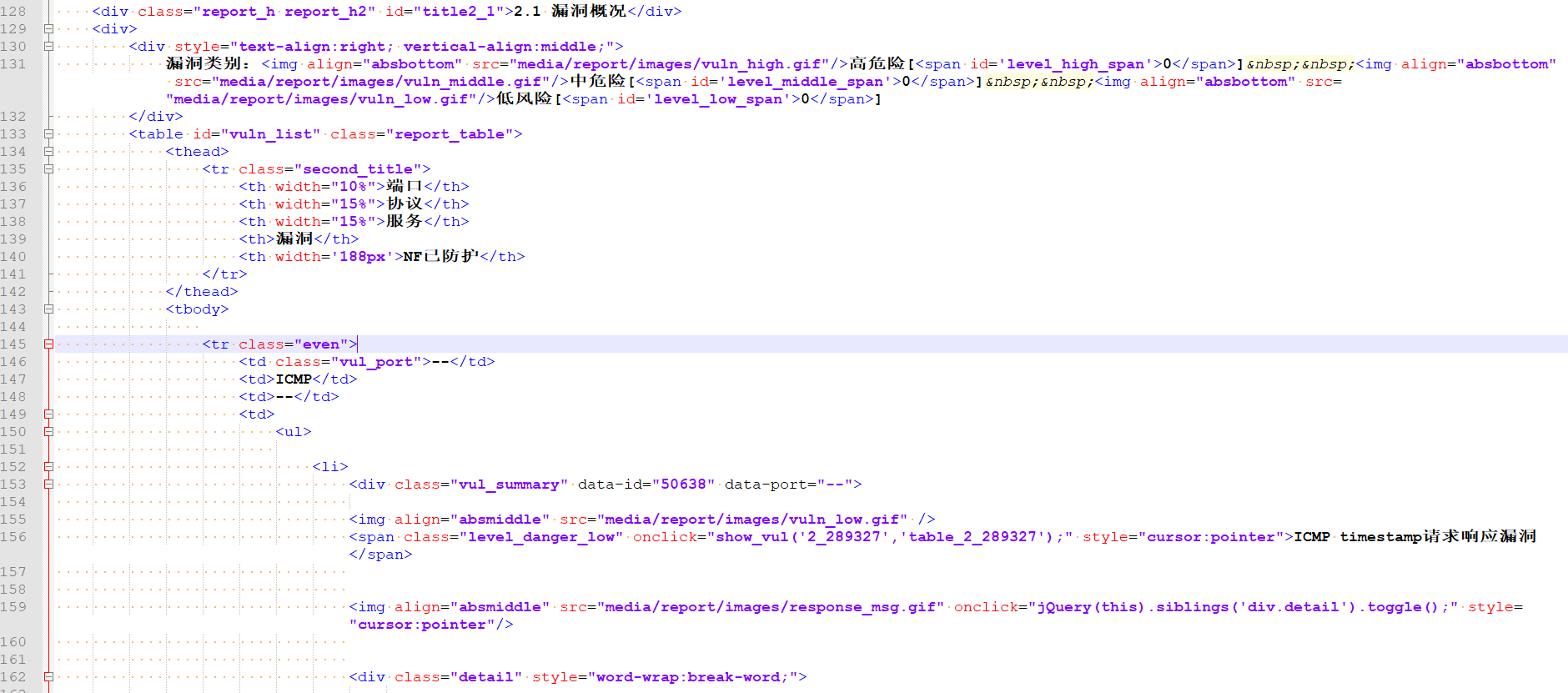
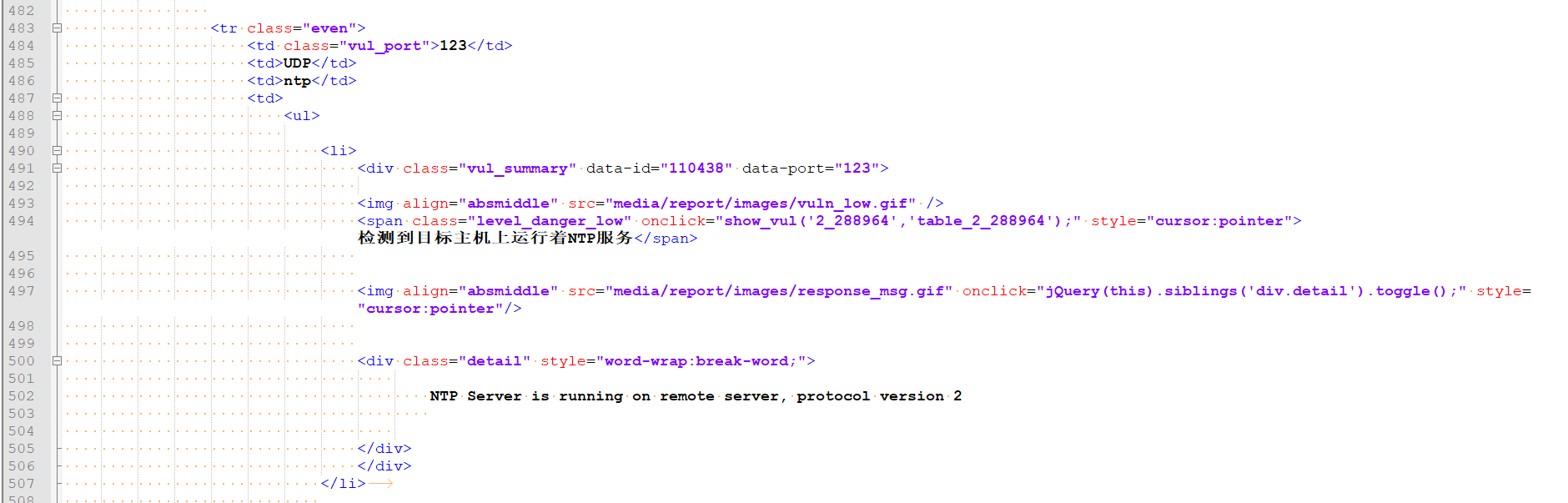
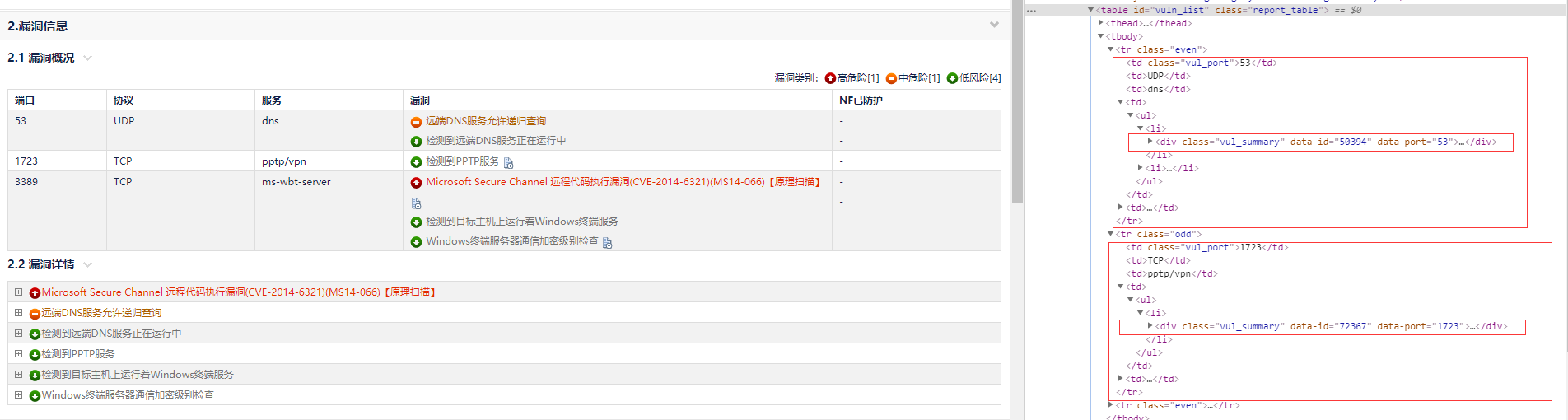
查看 html 源码中,发现 div.vul_summary 主要为漏洞名称、开放端口,和一些其它标签值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 for node in vul_node:"data-port" ]'span' )'class' ][0 ]'onclick' ]if vulname == "Portable OpenSSH 'ssh-keysign'本地未授权访问漏洞" :'CVE-2011-4327' elif vulname == "Portable OpenSSH 'ssh-keysign'本地未授权访问漏洞" :'CVE-2011-4327' else :'cve' ]print (ip, vulname)list = [ip, vultype, vulrisk, vulcve, vulname, allvul['desc' ], allvul['advice' ], port, service, Agreement] if vulrisk == '低' :pass else :list )
通过遍历 div.vul_summary 区域的部分,最终获取到了主机类型、风险等级、CVE编号、漏洞名称、漏洞描述、整改意见、开放端口。
但是,在输出结果时,把漏洞等级为低的,全部过滤了,不进行输出。
第二十一行,list 为存放漏洞所有信息的列表,并且写入Excel中,我们需要在这里加上 “服务”、“协议” 两个变量名,这样再最后就会写入到Excel中。
0x05 分析两个字段
既然前后输出的字段列表中,我们已经提前写上了字段名,那就开始构造相应的变量吧。
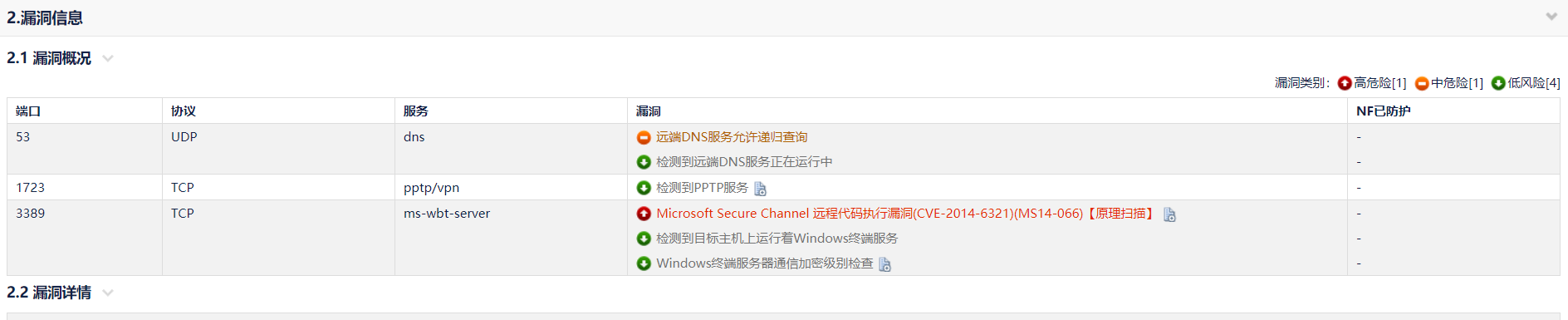
首先查看报告,可以看出,需求的两个字段,均在 2.1 漏洞概况中,其它地方均无可用的。
鼠标右键源码查看:
通过查看该部分,发现了一个问题,服务、协议,两个标签出,均没有属性,导致无法直接通过属性值来获取。
突然蒙蔽中,因为是用的 bs4 ,本身并没有用过,不是很熟悉,故此开始各种翻文档学习中。。。
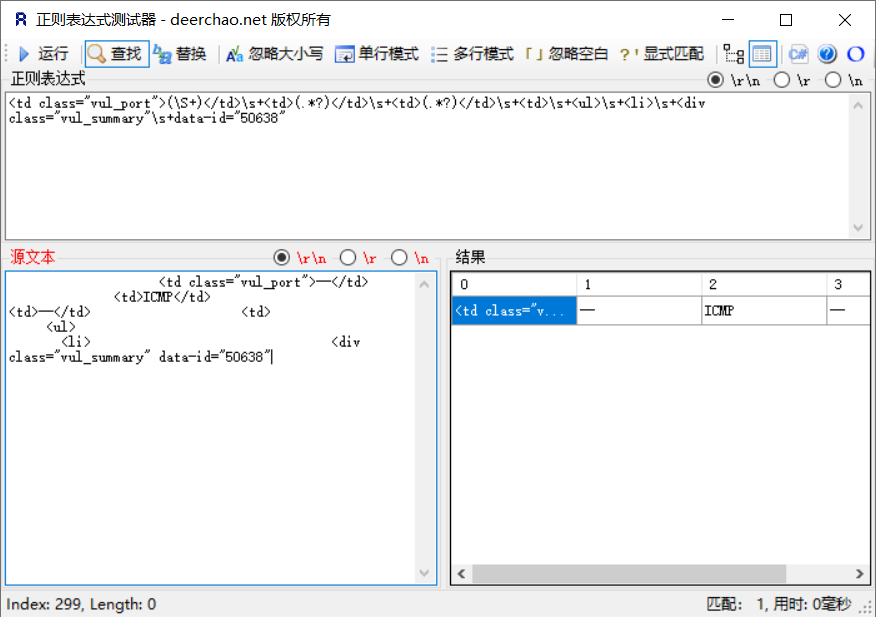
一开始思考着,直接使用正则匹配 <td class="vul_port">--</td> 和 <div class="vul_summary" 之间的部分,然后利用正则直接匹配所需值。并且我还调试了半天,调试出来的正则:
1 <td class ="vul_port" >(\S+)</td>\s+<td>(.*?)</td>\s+<td>(.*?)</td>\s+<td>\s+<ul>\s+<li>\s+<div class ="vul_summary'#" \s+data-id '="{}"' .format ('50394' )
通过这个正则,可以看到,我还想着利用 data-id 这个值来对应相对应的漏洞,结果出现问题了。
没错!data-id 的值并不是对应着一个开放端口和协议的,而是汇总到一起的。
此时,我陷入沉思中。。。
0x06 柳暗花明
与其没思路,不如求助大佬,求助大佬中。。。。
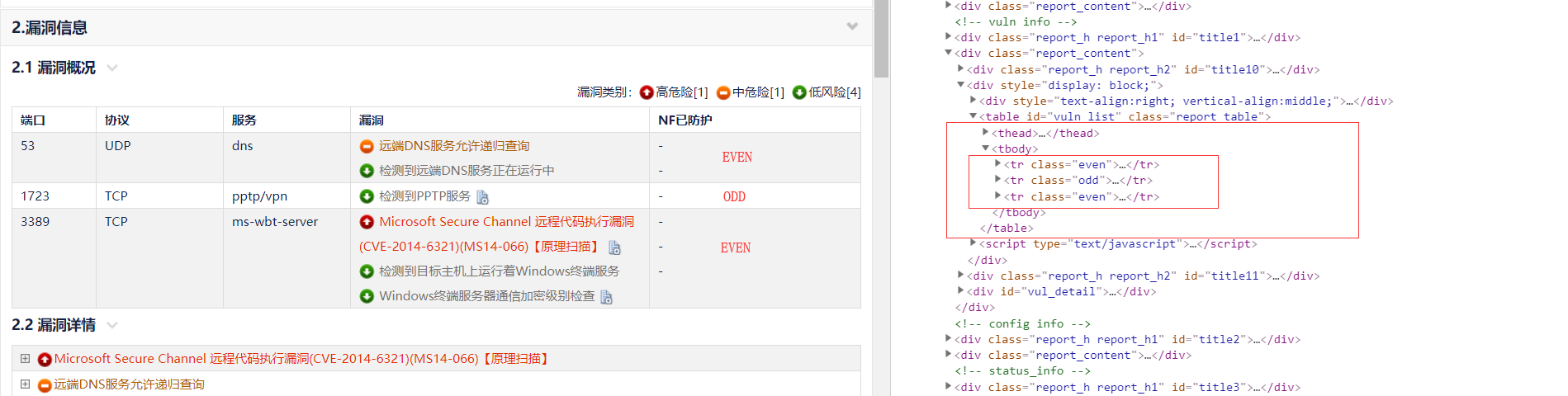
按照上述的方法,再继续看HTML源码,发现了一个特点:
1、整个漏洞概况储存在 id 为的 vuln_list 的 table 中,且该id值是唯一的。
2、核心部分位于 tbody 标签中。
3、tr 的 class 值为 even 为灰色,class 值为 odd 为白色。
至此,一开始我想的是写一个函数,来获取服务和协议的值,现在为何不在原始的 for 循环外,嵌套两个循环来解决该问题。
1 2 3 4 5 6 'div.vul_summary' )for node in vul_node:"data-port" ]
原始循环只是在 div.vul_summary 中循环,而 tr.even 和 tr.odd 都是包含 div.vul_summary 的,故此可以在原始循环外面嵌套几个大的循环。
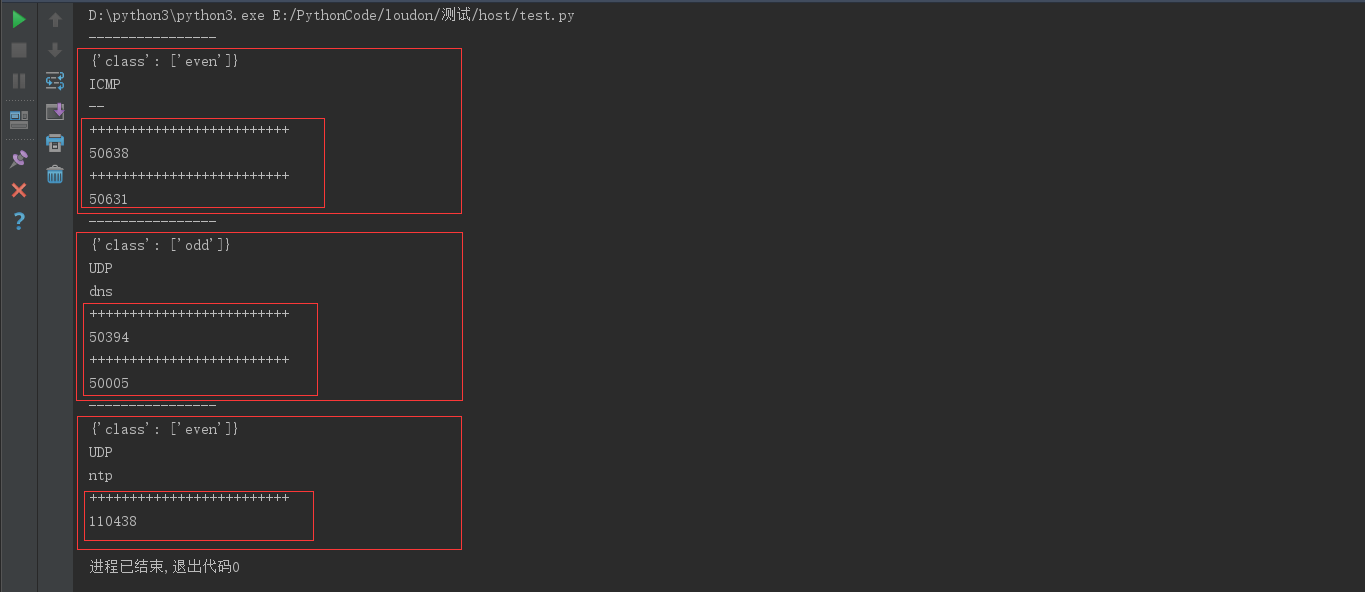
为了验证这个想法是可行的,简单的写了一个dome来测试,看看。
dome code 就不贴了,太丑了。
至此,成功的获取到了 服务 和 协议 两个想要的值。
获取两个字段值的最终 code 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 'table' , id ='vuln_list' )for Vulnerability_area in Vulnerability_List:'tr' )for tr_even_odd in va_tbody_tr:str (atters_list[3 ])'<td>(.*?)</td>' 0 ] str (atters_list[5 ])0 ]
0x07 扩展学习①
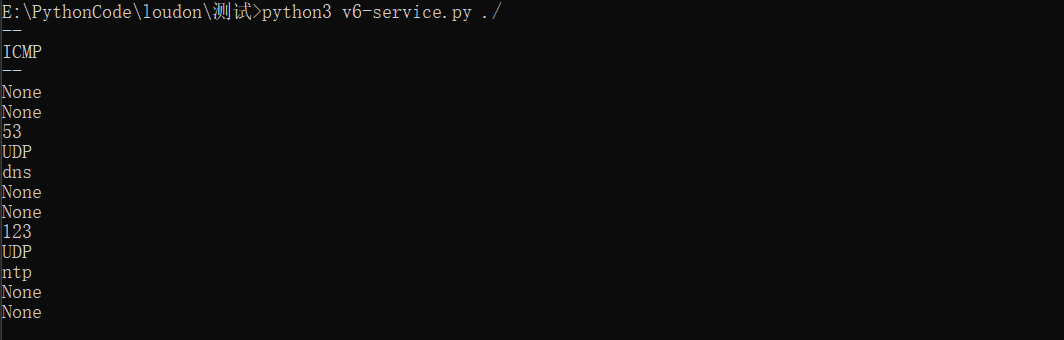
刚刚把我的这部分写完,并且测试也没啥问题时,上文中的大佬也完成了他写的,我看了下,和我的方法不太一致,主要是按照他一开始说的那个思路写的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 0 for vul_node1 in soup.find(id ="vuln_list" ).findAll("tr" ):1 if x >= 2 :len (vul_node1.findAll('span' ))for i in vul_node1:if isinstance (i, bs4.element.Tag):str (i.string))for z in range (num):print (vul_service_sum)'div.vul_summary' )0 for node in vul_node:"data-port" ]'span' )'class' ][0 ]'onclick' ]if vulname == "Portable OpenSSH 'ssh-keysign'本地未授权访问漏洞" :'CVE-2011-4327' elif vulname == "Portable OpenSSH 'ssh-keysign'本地未授权访问漏洞" :'CVE-2011-4327' else :'cve' ]list = [ip, vultype, vulrisk, vulcve, vulname, allvul['desc' ], allvul['advice' ], port,vul_service_sum[y][2 ],vul_service_sum[y][1 ]]1 if vulrisk == '低' :pass else :list )
思路流程如下:
1、获取 table.vuln_list 中所有被 tr 包围的部分。
2、通过span标签来识别漏洞数量
3、对获取的 tr 包围的部分,如果数据类型为 bs4.element.Tag ,储存到 vul_service 列表中,该列表储存基本均是端口号、服务、协议。
4、通过获取的漏洞数,来重复放置识别出的值。
分割线上方为 vul_service 列表的值,下方为 vul_service_sum 的值。
5、 最后通过 node 每轮遍历的 y 值,来对应使用哪个服务和协议。
6、不好理解的话,可以拿code进行debug一下,能加深理解。
0x08 扩展学习②
把上述两个方法整合了一下,感觉下面的这个更简单。
1 2 3 4 5 6 7 8 9 10 id ="vuln_list" ).findAll("tr" )for tr_even_odd in Vulnerability_List:for x in tr_even_odd:if isinstance (x, bs4.element.Tag):str (x.string))2 ] 1 ]
0x09 后续
因标题只是针对新增的两个字段的,故没有对剩下的函数模块,进行分析。
其它函数,也是很不错的,比如 gettype() 函数模块,通过匹配漏洞名称里的关键词,来确认主机类型,因为报告中,确实没有显示该主机类型。